Wireshark es un analizador de paquetes multiplataforma, indispensable para hacer troubleshooting en networking. Cuando surge la necesidad de escribir software que involucre algún tipo de comunicación remota entre 2 o más puntas, muchas veces los problemas de comunicación aparecen. Wireshark es espectacular para depurar este tipo de problemas y hoy por hoy es la herramienta de análisis de tráfico (de red) número uno alrededor del mundo.
Estructuralmente está dividido es una serie de paquetes a los cuales se les llama disectores. Aunque Wireshark es capaz de capturar cualquier tipo de paquetes, el payload o carga útil puede no ser legible si no contamos con un disector especializado que lo corte en porciones entendibles a simple vista.
Disector
Básicamente, es un plugin que el programa principal carga para descomponer convenientemente un paquete que responde a las características que el disector determina. Por ejemplo, si llega un paquete en puerto 6789, utilizando como transporte TCP y existe un plugin cargado con éstas dos condiciones satisfechas, el Wireshark utilizará nuestro plugin para descomponer el paquete y mostrarnos su contenido de acuerdo a lo que nosotros hayamos especificado.
El disector es un programa escrito en C que debe ser compilado como shared object (DLL en Windows) y debe contener una serie de funciones estándares a los que Wireshark llamará en tiempo de ejecución para registrar el plugin. La carga del mismo responde al comportamiento típico de dynamic linking, visible en la grandiosa mayoría del software moderno escrito de manera modular.
El protocolo CRD
Me tocó hacer un disector de un protocolo complejo pero, por fines pedagógicos, decidí crear uno súper sencillo (al que llamaremos CRD) de modo a demostrar que escribir extensiones no es tan complicado como parece y más bien requiere invertir tiempo en leer la documentación y alguno que otro disector de ejemplo disponible en el
trunk de su repositorio
SVN.
Abajo especifico la estructura del protocolo. Cuenta con tres campos definidos de la siguiente manera:
TipoMensaje: determina si el mensaje es de petición o de respuesta.

CódigoRespuesta: determina el resultado de la operación a través de un código numérico.
Mensaje:texto de longitud variable enviado como anexo a la respuesta.
Juntando todos los campos quedamos así:

Ahora que tenemos nuestro protocolo definido podemos empezar la captura pero para esto necesitamos hacer un servidor TCP que nos responda un string válido con las características de nuestro protocolo y con este propósito en mente, escribí un script PHP que responda a eventuales clientes con un texto predeterminado.
[php] $message1 = “01hola mundo a las “;
$socket = stream_socket_server(“tcp://localhost:9999”, $errno, $errstr, STREAM_SERVER_BIND | STREAM_SERVER_LISTEN);
for(;;) { $client = stream_socket_accept($socket);
fwrite($client, $message1.date(“Y-m-d h:i:s”));
fclose($client);
}[/php]
Con este sencillo
script al conectarnos a
localhost en puerto 9999 utilizando
telnet por ejemplo, obtenemos el siguiente resultado:
[bash]carlos@carlosrd-laptop:~> telnet localhost 9999
Trying 127.0.0.1…Connected to localhost.Escape character is ‘^]’
.01hola mundo a las 2010-11-13 05:47:13
[/bash]
Ahora, cómo se ve esa captura desde el Wireshark sin nuestro disector?
La verdad que se ve horrible aunque no sea muy difícil leerlo pero cuando trabajemos con un protocolo real, tratar de hacer una lectura comprensiva exitosa desde la vista de arriba, nos tomaría el doble de tiempo y esfuerzo.
Haciendo el disector
Para escribir un disector se necesita tener un conocimiento medio-avanzado del lenguaje C, mientras más complejo sea nuestro protocolo, más difícil será crearle un disector. Además de C, es necesario leer extensivamente la documentación del
developer disponible
aquí. No pretendo transcribir lo que ya está escrito porque sería una perdida de tiempo así que es muy importante leer el manual antes de seguir. Una vez terminado eso, se necesita tener el ambiente de desarrollo listo para compilar nuestro
plugin:
- Tener instalado los fuentes del Wireshark o haciendo svn checkout de su repositorio
- Tener instalado los archivos de cabecera de libpcap
- Tener instalado automake
La lista de requisitos continúa pero en general no suele ser necesario instalar nada más que lo arriba mencionado.
En mi caso particular de usuario de Linux, tener el ambiente listo me tomó menos de 5 minutos. Si usás Windows esto se puede llegar a complicar (bastante) pero es igualmente posible y documentación sobre cómo hacerlo está disponible en Internet.
El código está comentado en porciones que consideré necesarias. Comenté muy poco lo que ciertas funciones usadas hacen porque eso es más bien ámbito del manual del desarrollador.
Bueno, show me the code:
[C]
/*** CRD Protocol dissector** Carlos Ruiz Díaz** carlos.ruizdiaz@gmail.com* http://tebicuary.blogspot.com/* @caruizdiaz** Asunción, Paraguay – November 2010**/
//#define IGNORE
#ifndef IGNORE
#ifdef HAVE_CONFIG_H# include “config.h”#endif
#include <stdio.h>#include <epan/packet.h>#include <string.h>
/** Protocol Logic Implementation*/
#define _REQUEST_VALUE 0#define _RESPONSE_VALUE 1
/** Definimos el nombre corto del protocolo que aparecerá en la vista* de disectores instalados**/#define PROTO_TAG_CRD “CRD”
/** Variable que contiene el ID que será asignado dinámicamente a nuestro disector por el Wireshark*/static int proto_crd = -1;
static dissector_handle_t data_handle = NULL;static dissector_handle_t crd_handle = NULL;
static void dissect_crd(tvbuff_t *tvb, packet_info *pinfo, proto_tree *tree);static void dissect_content(tvbuff_t *tvb, proto_tree *tree);static void substr(const char* origin, int start, int length, char* result);
/** Puerto por defecto en el que el protocolo opera*/static int global_crd_port = 9999;
/** value_string es una estructura especializada creada para hacer lookups* usando la función val_to_str() a través de una clave.** Abajo definimos la lista de posibles valores que puede contener el campo* nro. 2 de nuestro protocolo. Los nros. corresponden al valor transportado* y la descripción literal a su significado.*/static const value_string transaction_result_names[] ={{ 00, “Proceso Exitoso” },{ 01, “Error de proceso” },{ 02, “Estado desconocido” }};
static gint hf_crd_pdu = -1;static gint hf_crd_body_data = -1;
static gint ett_crd_pdu = -1;static gint ett_crd_body_data = -1;
void proto_reg_handoff_crd(void){static gboolean initialized = FALSE;
if (!initialized){data_handle = find_dissector(“data”);crd_handle = create_dissector_handle(dissect_crd, proto_crd);dissector_add(“tcp.port”, global_crd_port, crd_handle);}}
void proto_register_crd(void){static hf_register_info hf[] ={{ &hf_crd_pdu,{ “PDU”, “crd”, FT_STRING, BASE_NONE, NULL, 0x0, “CRD PDU”, HFILL }},
{ &hf_crd_body_data,{ “Body”, “crd.body”, FT_NONE, BASE_NONE, NULL, 0x0, “CRD Body contents”, HFILL }}};
static gint *ett[] ={&ett_crd_pdu,&ett_crd_body_data};
proto_crd = proto_register_protocol(“CRD Protocol – Ejemplo de uso”, “CRD”, “crd”);
proto_register_field_array (proto_crd, hf, array_length (hf));proto_register_subtree_array (ett, array_length (ett));
register_dissector(“crd”, dissect_crd, proto_crd);}
static void dissect_crd(tvbuff_t *tvb, packet_info *pinfo, proto_tree *tree){/** De acuerdo a la definición de protocolo, el primer byte indica el tipo de mensaje que es.* 0 para request* 1 para response** Obtenemos el primer byte y lo convertimos a entero*/int type = atoi(tvb_get_string(tvb, 0, 1));
/** Chequeamos si en la columna puede escribirse, si se puede,* escribimos en ella el nombre del protocolo*/if (check_col(pinfo->cinfo, COL_PROTOCOL))col_set_str(pinfo->cinfo, COL_PROTOCOL, PROTO_TAG_CRD);
if (check_col(pinfo->cinfo, COL_INFO)){col_clear(pinfo->cinfo, COL_INFO);
/** En el cuadro de paquetes capturados, cuando se reciba uno que coincida con nuestro protocolo,* escribimos como etiqueta el puerto de origen, el de destino y el tipo de mensaje.*/col_add_fstr(pinfo->cinfo, COL_INFO, “%d > %d Message Type: [%s]”,pinfo->srcport, pinfo->destport,((type == _REQUEST_VALUE) ? “REQUEST” : “RESPONSE”));}
/** Si la variable tree es NULL, significa que el usuario no expandió el árbol de captura,* entonces retornamos porque no hay nada que mostrar*/if (tree == NULL)return;
dissect_content(tvb, tree);
}
static void dissect_content(tvbuff_t *tvb, proto_tree *tree){proto_item *ti = NULL;
/* PDU */proto_tree *pdu_tree = NULL;proto_item *pdu_item = NULL;
/* BODY */proto_tree *body_tree = NULL;proto_item *body_item = NULL;
/** Obtenemos la longitud del mensaje*/int message_length = tvb_reported_length(tvb);
/** Lo guardamos en un buffer temporal de modo a simplificar el código*/char message[message_length + 1];
/** Creamos la variable que contendrá el estado (numérico) de la transacción*/char transaction_result[3];
/** Contenido de longitud variable del texto del mensaje.*/int message_text_length = message_length – 2;char message_text[message_text_length];
/** Leemos del buffer de entrada desde el offset 0 hasta el final .*/strcpy(message, tvb_get_string(tvb, 0, message_length));
/** Extraemos 2 bytes del mensaje original obviando el marcador de tipo de mensaje*/substr(message, 1, 2, transaction_result);
/** Extraemos el texto del mensaje (de longitud variable) empezando desde el byte nro. 4* y hasta el final.*/substr(message, 2, message_text_length, message_text);
ti = proto_tree_add_item(tree, proto_crd, tvb, 0, -1, FALSE);
pdu_item = proto_tree_add_text(tree, tvb, 0, -1, “PDU”);body_item = proto_tree_add_text(tree, tvb, 0, -1, “Cuerpo”);
/* PDU subtree */pdu_tree = proto_item_add_subtree(pdu_item, ett_crd_pdu);proto_tree_add_text(pdu_tree, tvb, 0, -1, “Longitud: %d”, message_length);proto_tree_add_text(pdu_tree, tvb, 0, -1, “Contenido: %s”, message);
/* BODY subtree */body_tree = proto_item_add_subtree(body_item, ett_crd_body_data);proto_tree_add_text(body_tree, tvb, 0, -1, “Resultado: %s”, val_to_str((guint32) atoi(transaction_result), transaction_result_names, “Unknown (0x%02x)”));proto_tree_add_text(body_tree, tvb, 0, -1, “Mensaje: %s”, message_text);
}
static void substr(const char* origin, int start, int length, char* result){int currentIndex = 0;int i = 0;int end = start + length;
for(i = start; i < end; i++)result[currentIndex++] = origin[i];
}#endif // IGNORE
[/C]
Ahora que ya tenemos el programa listo, lo último que debemos hacer es:
- Llevar el código al directorio plugins de nuestro working copy y crearle un directorio con una estructura copiada de cualquier de otro plugin existente en el mismo directorio
- Crear entradas que referencien a nuestro disector en el archivo configure.in disponible en la raíz de nuestra copia
- Correr el script autogen.sh
- Correr el script configure
- Ir al directorio de nuestro plugin
- Compilar el plugin usando make
- Copiar el resultado de la compilación disponible en .libs/crd.so al directorio de plugins del Wireshark, en mi caso, /usr/lib/wireshark/plugins/1.0.4/
Con estos pasos, la próxima vez que abra el Wireshark, nuestro plugin estará cargado y listo para usarse.
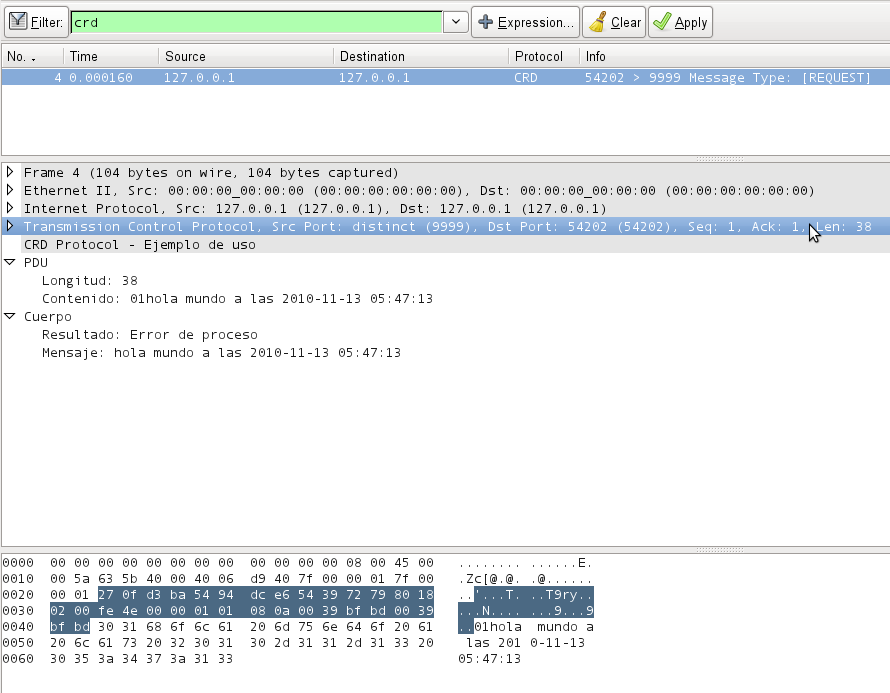
La misma captura que hicimos anteriormente deberá ser visible mucho más elegantemente y quedaría así:
En vez de tener un paquete capturado mostrando un texto plano, tenemos una separación por bloques, con una descripción de los códigos de los primeros dos campos y la separación del mensaje de respuesta en una etiqueta independiente. Este resultado es mucho más representativo y sin duda, mucho más útil que el anterior.
Eso es todo por ahora, gracias por la lectura 🙂 .